Zabbix 数据库优化及 MySQL/MariaDB 分区
前言
Zabbix 用久了以后,数据库基本都会成为最先需要处理的地方。
一开始可能只是页面慢一点,后面就会变成 housekeeper 忙、history 表越来越大、磁盘增长快、图形偶尔没数据,再严重一点就是插入历史数据也被拖住。
本文主要整理两部分内容:
- MySQL/MariaDB 作为 Zabbix 后端数据库时的基础优化参数
- 对 Zabbix 的 history 和 trends 表做 MySQL/MariaDB 分区
适用环境
数据库为 MySQL 或 MariaDB。
分区脚本用于 Zabbix 3.0 之后的版本,例如 3.2、3.4、4.0、4.2、4.4、5.0、5.2、5.4、6.0 等。
如果是 Zabbix 7.x 或 MySQL 8,建议先在测试库验证。脚本本身主要处理 history 和 trends 相关表,不处理 auditlog、service data 等其他表,这些内容继续交给 Zabbix 自带 housekeeping。
一、MySQL/MariaDB 配置优化
MySQL/MariaDB 的配置文件常见位置:
/etc/my.cnf
/etc/my.cnf.d/
/etc/mysql/mariadb.conf.d/
以下配置按独立数据库服务器来写,机器规格为 4 CPU、32GB 内存。实际使用时不要直接照抄,尤其是 innodb_buffer_pool_size 和 max_connections。
[mysqld]
# MySQL Server Configuration
# Directories and File Paths
datadir=/data/mysql
socket=/data/mysql/mysql.sock
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
# Logging and Replication
skip-log-bin=true
# Performance and Optimization
skip_name_resolve
skip-performance-schema
optimizer_switch = 'index_condition_pushdown=off'
tmp-table-size = 96M
max-heap-table-size = 96M
key_buffer_size = 64M
# Connections and Threads
max_connections = 1250
thread_cache_size = 8
max_allowed_packet = 64M
# InnoDB Configuration
innodb-log-file-size = 128M
innodb-log-buffer-size = 128M
innodb-file-per-table = 1
innodb_buffer_pool_instances = 8
innodb_old_blocks_time = 1000
innodb_stats_on_metadata = off
innodb-flush-method = O_DIRECT
innodb-flush-log-at-trx-commit = 2
innodb_buffer_pool_size = 23G
innodb_read_io_threads = 32
innodb_write_io_threads = 32
innodb_io_capacity = 4000
innodb_io_capacity_max = 6000
# Timeouts
connect_timeout = 300
wait_timeout = 30000
# Caches and Limits
table_open_cache_instances = 16
table_open_cache = 32012
open_files_limit = 65535
max_connect_errors = 1000000
[client]
# MySQL Client Configuration
socket=/data/mysql/mysql.sock
max_connections
max_connections 需要大于 Zabbix server 所有进程数之和,再额外加 150。
可以用下面命令粗略计算:
egrep "^Start.+=[0-9]" /etc/zabbix/zabbix_server.conf | awk -F "=" '{s+=$2} END {print s+150}'
示例输出:
295
如果算出来是 295,max_connections 至少要大于这个值。实际生产环境建议再留余量,尤其是有前端、脚本、BI、备份工具同时连数据库时。
innodb_buffer_pool_size
innodb_buffer_pool_size 是最重要的性能参数之一,用于缓存 InnoDB 表和索引数据。
如果数据库是独立服务器,可以设置为物理内存的 70% 左右。比如 32GB 内存,可以先设置到 23G。
如果 Zabbix server 和数据库在同一台机器上,或者机器上还有其他服务,不要按 70% 硬套。出现内存不足、数据库或 Zabbix 异常退出时,先降低这个值,再重启数据库。
参数说明
Performance and Optimization
| 参数 | 作用 | 取值说明 |
|---|---|---|
skip_name_resolve | 禁用客户端连接时的 DNS 解析,使用 IP 连接时可以减少解析开销 | 布尔参数 |
skip-performance-schema | 禁用 Performance Schema,减少额外统计开销 | 布尔参数 |
optimizer_switch | 控制优化器开关,这里关闭 index_condition_pushdown | 取决于 MySQL/MariaDB 支持的优化器开关 |
tmp-table-size | 单个会话内存临时表最大大小 | 最小 0,默认 16M,最大受内存限制 |
max-heap-table-size | MEMORY/HEAP 表最大大小 | 最小 0,默认 16M,最大受内存限制 |
key_buffer_size | MyISAM 索引缓存大小 | 最小 8M,默认 128M,最大受内存限制 |
optimizer_switch = 'index_condition_pushdown=off' 主要是为了绕过某些 Zabbix 慢查询问题。新版本环境可以单独测试,如果没有相关慢查询,不建议盲目把所有库都这样改。
Connections and Threads
| 参数 | 作用 | 取值说明 |
|---|---|---|
max_connections | 最大同时连接数 | 最小 1,默认 151,最大 100000 |
thread_cache_size | 可复用的连接线程缓存数量 | 最小 0,默认 9,最大 100000 |
max_allowed_packet | 单个 packet 或 BLOB/TEXT 字段最大大小 | 最小 1024,默认 16M,最大 1GB |
InnoDB Configuration
| 参数 | 作用 | 取值说明 |
|---|---|---|
innodb-log-file-size | 单个 InnoDB redo log 文件大小 | 最小 5M,默认 48M,最大受文件系统限制 |
innodb-log-buffer-size | InnoDB redo log buffer 大小 | 最小 1M,默认 16M,最大受内存限制 |
innodb-file-per-table | 每张 InnoDB 表使用独立表空间文件 | 布尔参数 |
innodb_buffer_pool_instances | 把 buffer pool 拆成多个实例,提高多线程访问效率 | 最小 1,默认 8,最大 64 |
innodb_old_blocks_time | block 在 old 子链表停留多久后进入 new 子链表 | 最小 1000,默认 1000,最大不限 |
innodb_stats_on_metadata | 元数据语句是否自动更新 InnoDB 统计信息 | on/off |
innodb-flush-method | InnoDB 数据文件刷盘方式 | 取决于系统支持的 flush method |
innodb-flush-log-at-trx-commit | 每次事务提交时 redo log 的刷盘策略 | 0、1、2,默认 1 |
innodb_buffer_pool_size | InnoDB 数据和索引缓存大小 | 最小 128M,默认 128M,最大受内存限制 |
innodb_read_io_threads | InnoDB 后台读 I/O 线程数 | 最小 1,默认 4,最大 64 |
innodb_write_io_threads | InnoDB 后台写 I/O 线程数 | 最小 1,默认 4,最大 64 |
innodb_io_capacity | InnoDB 后台 I/O 线程可使用的 IOPS | 最小 100,默认 200,最大 2^64-1 |
innodb_io_capacity_max | InnoDB 后台 I/O 线程可使用的最大 IOPS | 最小 2000,默认 2000,最大 2^64-1 |
Timeouts
| 参数 | 作用 | 取值说明 |
|---|---|---|
connect_timeout | 客户端建立连接的等待秒数 | 最小 2,默认 10,最大 31536000 |
wait_timeout | 非交互连接空闲多久后断开 | 最小 2,默认 28800,最大 31536000 |
Caches and Limits
| 参数 | 作用 | 取值说明 |
|---|---|---|
table_open_cache_instances | table cache 拆分实例数,减少并发竞争 | 最小 1,默认 1,最大 64 |
table_open_cache | 所有线程可打开表的数量 | 最小 1,默认 4000,最大 524288 |
open_files_limit | MySQL 可打开文件数限制 | 最小 1024,默认 65535,最大不限 |
max_connect_errors | 单个主机允许的中断连接错误次数 | 最小 1,默认 100,最大 18446744073709551615 |
二、Zabbix 历史表和趋势表分区
Zabbix 采集的数据主要进入两类表:
history系列表:保存原始采集值,也就是每一次采集的数据trends系列表:保存小时级聚合数据,包含 min、avg、max
Zabbix 自带 housekeeping 会清理旧数据,但它本质上是对旧数据做 delete。数据量大以后,delete 会拖慢数据库,常见现象就是:
Zabbix housekeeper processes more than 75% busy
分区的思路是按天或按小时拆分表分区,过期后直接 drop partition。drop 比 delete 快很多,也更适合 history、trends 这种按时间淘汰的数据。
备份
继续之前先备份数据库。
mysqldump -uroot -p --single-transaction zabbix | gzip > /opt/zabbix_backup_$(date +%F).sql.gz
三、创建分区 SQL 脚本
脚本文件名为 zbx_db_partitiong.sql,脚本内容如下:
DELIMITER $$
CREATE PROCEDURE `partition_create`(SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64), CLOCK int)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
PARTITIONNAME = The name of the partition to create
*/
/*
Verify that the partition does not already exist
*/
DECLARE RETROWS INT;
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_description >= CLOCK;
IF RETROWS = 0 THEN
/*
1. Print a message indicating that a partition was created.
2. Create the SQL to create the partition.
3. Execute the SQL from #2.
*/
SELECT CONCAT( "partition_create(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" ) AS msg;
SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_drop`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), DELETE_BELOW_PARTITION_DATE BIGINT)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
DELETE_BELOW_PARTITION_DATE = Delete any partitions with names that are dates older than this one (yyyy-mm-dd)
*/
DECLARE done INT DEFAULT FALSE;
DECLARE drop_part_name VARCHAR(16);
/*
Get a list of all the partitions that are older than the date
in DELETE_BELOW_PARTITION_DATE. All partitions are prefixed with
a "p", so use SUBSTRING TO get rid of that character.
*/
DECLARE myCursor CURSOR FOR
SELECT partition_name
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND CAST(SUBSTRING(partition_name FROM 2) AS UNSIGNED) < DELETE_BELOW_PARTITION_DATE;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
/*
Create the basics for when we need to drop the partition. Also, create
@drop_partitions to hold a comma-delimited list of all partitions that
should be deleted.
*/
SET @alter_header = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " DROP PARTITION ");
SET @drop_partitions = "";
/*
Start looping through all the partitions that are too old.
*/
OPEN myCursor;
read_loop: LOOP
FETCH myCursor INTO drop_part_name;
IF done THEN
LEAVE read_loop;
END IF;
SET @drop_partitions = IF(@drop_partitions = "", drop_part_name, CONCAT(@drop_partitions, ",", drop_part_name));
END LOOP;
IF @drop_partitions != "" THEN
/*
1. Build the SQL to drop all the necessary partitions.
2. Run the SQL to drop the partitions.
3. Print out the table partitions that were deleted.
*/
SET @full_sql = CONCAT(@alter_header, @drop_partitions, ";");
PREPARE STMT FROM @full_sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, @drop_partitions AS `partitions_deleted`;
ELSE
/*
No partitions are being deleted, so print out "N/A" (Not applicable) to indicate
that no changes were made.
*/
SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, "N/A" AS `partitions_deleted`;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_maintenance`(SCHEMA_NAME VARCHAR(32), TABLE_NAME VARCHAR(32), KEEP_DATA_DAYS INT, HOURLY_INTERVAL INT, CREATE_NEXT_INTERVALS INT)
BEGIN
DECLARE OLDER_THAN_PARTITION_DATE VARCHAR(16);
DECLARE PARTITION_NAME VARCHAR(16);
DECLARE OLD_PARTITION_NAME VARCHAR(16);
DECLARE LESS_THAN_TIMESTAMP INT;
DECLARE CUR_TIME INT;
CALL partition_verify(SCHEMA_NAME, TABLE_NAME, HOURLY_INTERVAL);
SET CUR_TIME = UNIX_TIMESTAMP(DATE_FORMAT(NOW(), '%Y-%m-%d 00:00:00'));
SET @__interval = 1;
create_loop: LOOP
IF @__interval > CREATE_NEXT_INTERVALS THEN
LEAVE create_loop;
END IF;
SET LESS_THAN_TIMESTAMP = CUR_TIME + (HOURLY_INTERVAL * @__interval * 3600);
SET PARTITION_NAME = FROM_UNIXTIME(CUR_TIME + HOURLY_INTERVAL * (@__interval - 1) * 3600, 'p%Y%m%d%H00');
IF(PARTITION_NAME != OLD_PARTITION_NAME) THEN
CALL partition_create(SCHEMA_NAME, TABLE_NAME, PARTITION_NAME, LESS_THAN_TIMESTAMP);
END IF;
SET @__interval=@__interval+1;
SET OLD_PARTITION_NAME = PARTITION_NAME;
END LOOP;
SET OLDER_THAN_PARTITION_DATE=DATE_FORMAT(DATE_SUB(NOW(), INTERVAL KEEP_DATA_DAYS DAY), '%Y%m%d0000');
CALL partition_drop(SCHEMA_NAME, TABLE_NAME, OLDER_THAN_PARTITION_DATE);
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_verify`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), HOURLYINTERVAL INT(11))
BEGIN
DECLARE PARTITION_NAME VARCHAR(16);
DECLARE RETROWS INT(11);
DECLARE FUTURE_TIMESTAMP TIMESTAMP;
/*
* Check if any partitions exist for the given SCHEMANAME.TABLENAME.
*/
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_name IS NULL;
/*
* If partitions do not exist, go ahead and partition the table
*/
IF RETROWS = 1 THEN
/*
* Take the current date at 00:00:00 and add HOURLYINTERVAL to it. This is the timestamp below which we will store values.
* We begin partitioning based on the beginning of a day. This is because we don't want to generate a random partition
* that won't necessarily fall in line with the desired partition naming (ie: if the hour interval is 24 hours, we could
* end up creating a partition now named "p201403270600" when all other partitions will be like "p201403280000").
*/
SET FUTURE_TIMESTAMP = TIMESTAMPADD(HOUR, HOURLYINTERVAL, CONCAT(CURDATE(), " ", '00:00:00'));
SET PARTITION_NAME = DATE_FORMAT(CURDATE(), 'p%Y%m%d%H00');
-- Create the partitioning query
SET @__PARTITION_SQL = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " PARTITION BY RANGE(`clock`)");
SET @__PARTITION_SQL = CONCAT(@__PARTITION_SQL, "(PARTITION ", PARTITION_NAME, " VALUES LESS THAN (", UNIX_TIMESTAMP(FUTURE_TIMESTAMP), "));");
-- Run the partitioning query
PREPARE STMT FROM @__PARTITION_SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
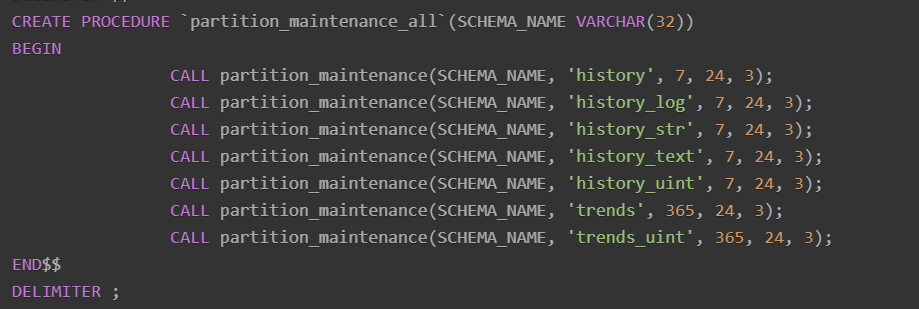
CREATE PROCEDURE `partition_maintenance_all`(SCHEMA_NAME VARCHAR(32))
BEGIN
CALL partition_maintenance(SCHEMA_NAME, 'history', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_log', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_str', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_text', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends', 365, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 365, 24, 3);
END$$
DELIMITER ;
默认配置:
- history 系列表保留 7 天
- trends 系列表保留 365 天
- 每 24 小时一个分区
- 预创建未来 3 个分区
如果要修改 history 或 trends 保留天数,改 partition_maintenance_all 过程里的数字即可。
四、导入分区过程
语法如下:
mysql -u '<db_username>' -p'<db_password>' <zb_database_name> < zbx_db_partitiong.sql
例如数据库名、用户名都是 zabbix,密码为 zabbixDBpass:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix < zbx_db_partitiong.sql
新安装的 Zabbix 执行会很快。
如果是很大的老库,可能会跑几个小时,所以不要在业务高峰期做。
五、让分区过程自动运行
前面只是创建了存储过程,存储过程不会自己运行。
必须定期执行 partition_maintenance_all('zabbix'),每天创建新分区并删除旧分区。这里有两种方式。
如果配置错,Zabbix 可能停止写入历史数据,图形会变空,日志里可能出现:
[Z3005] query failed: [1526] Table has no partition for value ...
方式一:MySQL event scheduler
推荐使用 MySQL event scheduler。
默认 event scheduler 是关闭的,需要在 MySQL/MariaDB 配置文件 [mysqld] 下面增加:
[mysqld]
event_scheduler = ON
不知道配置文件在哪,可以搜索:
sudo grep --include=*.cnf -irl / -e "\[mysqld\]"
修改后重启数据库:
sudo systemctl restart mysql
检查是否启用:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "SHOW VARIABLES LIKE 'event_scheduler';"
正常输出类似:
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| event_scheduler | ON |
+-----------------+-------+
创建定时事件,每 12 小时执行一次分区维护:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CREATE EVENT zbx_partitioning ON SCHEDULE EVERY 12 HOUR DO CALL partition_maintenance_all('zabbix');"
12 小时后检查 event 是否执行过:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "SELECT * FROM INFORMATION_SCHEMA.events\G"
关注输出里的 LAST_EXECUTED:
EVENT_CATALOG: def
...
CREATED: 2020-10-24 11:01:07
LAST_ALTERED: 2020-10-24 11:01:07
LAST_EXECUTED: 2020-10-24 11:43:07
...
方式二:Crontab
如果不能用 event scheduler,也可以用 crontab。
打开 crontab:
sudo crontab -e
每天凌晨 03:30 执行:
30 03 * * * /usr/bin/mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all('zabbix');" > /tmp/CronDBpartitiong.log 2>&1
日志会写入:
/tmp/CronDBpartitiong.log
如果想立即执行一次:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all('zabbix');"
可能看到类似输出:
+-----------------------------------------------------------+
| msg |
+-----------------------------------------------------------+
| partition_create(zabbix,history,p201910150000,1571180400) |
+-----------------------------------------------------------+
...
检查 history 表分区:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "show create table history\G"
输出里能看到 PARTITION BY RANGE (clock):
Table: history
Create Table: CREATE TABLE history (
itemid bigint(20) unsigned NOT NULL,
clock int(11) NOT NULL DEFAULT '0',
value double(16,4) NOT NULL DEFAULT '0.0000',
ns int(11) NOT NULL DEFAULT '0',
KEY history_1 (itemid,clock)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
/*!50100 PARTITION BY RANGE (clock)
(PARTITION p201910140000 VALUES LESS THAN (1571094000) ENGINE = InnoDB,
PARTITION p201910150000 VALUES LESS THAN (1571180400) ENGINE = InnoDB,
PARTITION p201910160000 VALUES LESS THAN (1571266800) ENGINE = InnoDB) */
这个示例里已经创建了 3 个 history 分区。
六、Zabbix 前端 housekeeping(管家)设置
分区配置完以后,还需要到 Zabbix 前端调整 housekeeping,中文界面里这里翻译为“管家”。
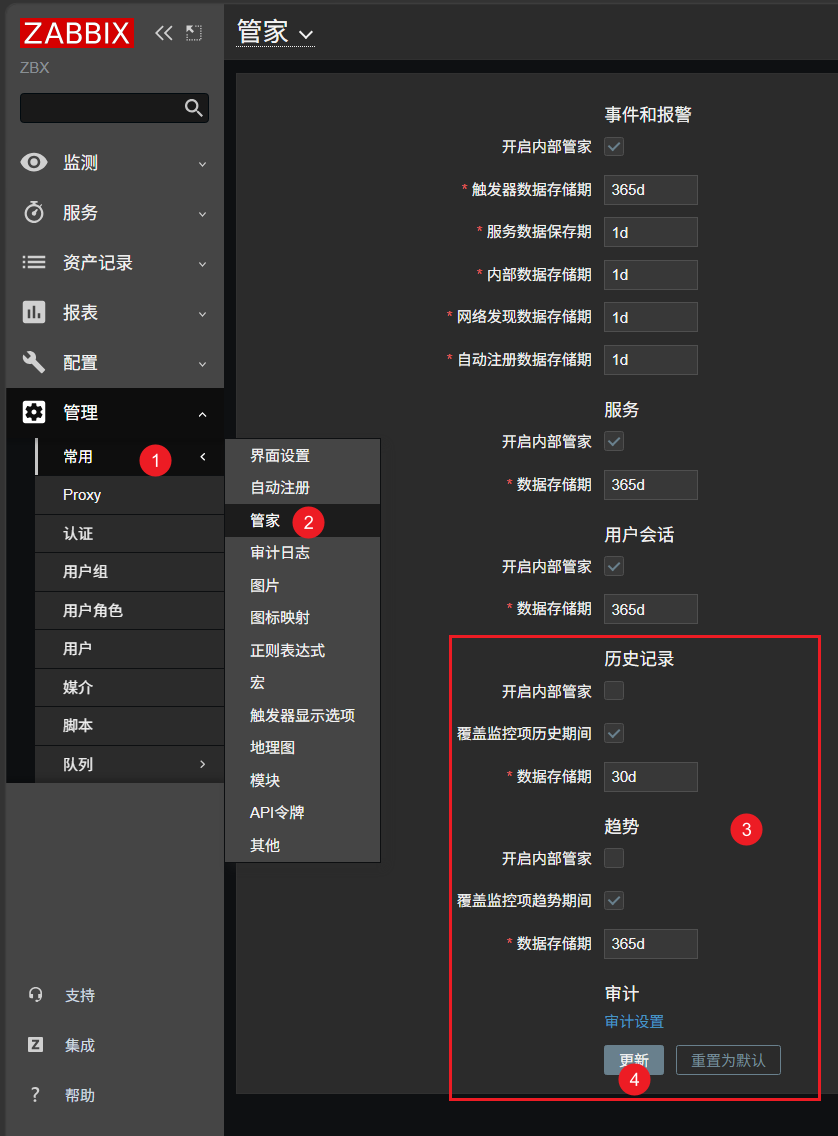
进入:
管理 -> 常用 -> 管家
Administration -> General -> Housekeeping
然后配置:
- 在 history 和 trends 相关位置取消勾选
启用内部管家,英文界面为Enable internal housekeeping - 勾选 history 的覆盖保留周期,英文界面为
Override item history period - 勾选 trends 的覆盖保留周期,英文界面为
Override item trend period - history 和 trends 的保留天数要和数据库分区过程一致
- 点击
更新,英文界面为Update
如果脚本默认不改,就是 history 保留 7 天,trends 保留 365 天。
需要注意:
- 分区真正决定数据删除时间
- 如果 history 配置 7 天,第 8 天开始删除旧 history 分区
- 删除以后每天删除一个 history 分区,使数据库始终保留 7 天 history 数据
- trends 配置 365 天时,要 365 天之后才开始删除旧 trends 分区
- 除 history 和 trends 外,其他 housekeeping(管家)项仍然交给 Zabbix 自己处理
七、修改 history 和 trends 保留天数
如果一开始保留太多,磁盘增长太快,或者一开始保留太少,需要修改保留时间,不需要重新导入整个 SQL。
直接创建一个新的维护过程,然后让 event scheduler 或 crontab 调用新过程。
连接数据库:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix
比如 history 改成 30 天,trends 改成 400 天:
DELIMITER $$
CREATE PROCEDURE partition_maintenance_all_30and400(SCHEMA_NAME VARCHAR(32))
BEGIN
CALL partition_maintenance(SCHEMA_NAME, 'history', 30, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_log', 30, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_str', 30, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_text', 30, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 30, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends', 400, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 400, 24, 3);
END$$
DELIMITER ;
如果使用 event scheduler,更新 event:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "ALTER EVENT zbx_partitioning ON SCHEDULE EVERY 12 HOUR DO CALL partition_maintenance_all_30and400('zabbix');"
如果使用 crontab,注释旧任务,增加新任务:
# old procedure, still exists in the database so it can be used if needed
# 30 03 * * * /usr/bin/mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all('zabbix');" > /tmp/CronDBpartitiong.log 2>&1
30 03 * * * /usr/bin/mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all_30and400('zabbix');" > /tmp/CronDBpartitiong.log 2>&1
保存退出即可。
八、常见错误处理
Duplicate partition name
如果 MySQL 的时间和 Linux 系统时间不一致,可能会出现重复分区名:
ERROR 1517 (HY000) at line 1: Duplicate partition name p202307100000
检查 MySQL 时间:
SELECT CURRENT_TIMESTAMP;
检查系统时间:
timedatectl
如果不一致,先修正系统时区和时间,再重启 MySQL/MariaDB。
Waiting for table metadata lock
分区脚本会修改 history 和 trends 表的元数据。
如果其他查询持有这些表的 metadata lock,分区过程会卡住,后续插入 history/trends 的 Zabbix 查询也会被堵住,表现出来就是图形没数据。
这不是分区脚本本身的问题,通常是其他脚本或应用占用了 Zabbix 表。
先看当前连接:
SHOW FULL PROCESSLIST;
查看 InnoDB 事务:
SELECT * FROM information_schema.INNODB_TRX \G;
查看 sleeping 状态查询的更多信息:
SELECT
performance_schema.threads.PROCESSLIST_ID,
performance_schema.threads.THREAD_ID,
performance_schema.events_statements_current.SQL_TEXT,
information_schema.INNODB_TRX.trx_started
FROM performance_schema.threads
INNER JOIN information_schema.INNODB_TRX
ON performance_schema.threads.PROCESSLIST_ID = information_schema.INNODB_TRX.trx_mysql_thread_id
INNER JOIN performance_schema.events_statements_current
ON performance_schema.events_statements_current.THREAD_ID = performance_schema.threads.THREAD_ID\G;
临时处理可以在执行分区脚本前杀掉指定用户的 sleeping 查询,例如 scriptuser 和 crmapp:
/usr/bin/mysql -u'root' -p'MyRootPass2!?' -e "SELECT GROUP_CONCAT(CONCAT('KILL ', id) SEPARATOR ';') AS kill_commands FROM information_schema.processlist WHERE db = 'zabbix' AND user IN ('scriptuser', 'crmapp') AND command = 'Sleep'" | grep -v '^kill_commands$' | /usr/bin/mysql -u'root' -p'MyRootPass2!?'
如果要作用于所有非 Zabbix 用户,可以把条件改成:
AND user != 'zabbix'
并去掉 AND user IN (...)。
生产环境不要无脑 kill,先确认这些连接是什么应用发起的。
九、分区过程说明
脚本里一共有 5 个过程。
partition_create
用于创建新分区。
它会先查 information_schema.partitions,确认不存在覆盖当前时间范围的分区,再执行:
ALTER TABLE ... ADD PARTITION ...
并输出创建信息。
partition_drop
用于删除旧分区。
逻辑是:
- 从
information_schema.partitions找到当前表所有分区 - 去掉分区名前面的
p - 把分区日期转成数字
- 小于保留日期的分区加入删除列表
- 执行
ALTER TABLE ... DROP PARTITION ...
如果没有需要删除的分区,会输出 N/A。
partition_maintenance
这是核心维护过程。
它做三件事:
- 调用
partition_verify确认表已经分区 - 按
HOURLY_INTERVAL和CREATE_NEXT_INTERVALS创建未来分区 - 按
KEEP_DATA_DAYS删除过期分区
默认 HOURLY_INTERVAL = 24,也就是一天一个分区。
默认 CREATE_NEXT_INTERVALS = 3,也就是预创建 3 个未来分区。
partition_verify
用于检查表是否还没有分区。
如果表没有分区,会按 clock 字段创建 range 分区,并从当天 00:00:00 开始计算,避免生成类似 p201403270600 这种不整齐的分区名。
partition_maintenance_all
这个过程统一调用所有 history 和 trends 表:
CALL partition_maintenance(SCHEMA_NAME, 'history', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_log', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_str', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_text', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends', 365, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 365, 24, 3);
这里也是后期修改保留天数最常改的地方。